2. Software implementation¶
2.1. Architecture¶
2.1.1. General Architecture¶
The programme is composed on two categories:
Database extraction ( OSM to CSV/SQLite)
Database analysis
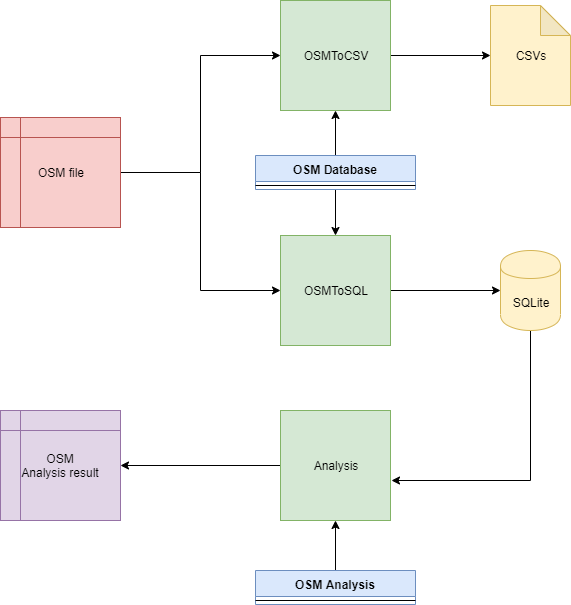
Legends:
OSMDatabase class manage OSM file by laoding ,audit and export it to CSV and SQLite
OSMAnalysis class manage SQLite database by allowinf several analysis functions
OSMToCSV main program allowing to transfom OSM file to CSV database files
OSMToSQL main program allowing to transfom OSM file to SQLite database
Analysis main program allowing to generate some database analysis
2.1.2. Database architecture¶
This database architecture comes from training. This database architecture is oriented from the data source.
nodes:
id : INTEGER (primary key)
lat : REAL
lon : REAL
user : TEXT
uid : INTEGER
version : INTEGER
changeset : INTEGER
timestamp : TEXT
nodes_tag:
id : INTEGER (foreign key to nodes.id)
key : TEXT
value : TEXT
type : TEXT
ways:
id : INTEGER (primary key)
user : TEXT
uid : INTEGER
version : INTEGER
changeset : INTEGER
timestamp : TEXT
ways_nodes:
id : INTEGER (foreign key to ways.id)
node_id INTEGER (foreign key to nodes.id)
position: INTEGER
ways_tags:
id : INTEGER (foreign key to ways.id)
key : TEXT
value : TEXT
type : TEXT
Note
Improvement: Instead to create node_tags and ways_tags table, we can create POI (Point of Interest) table to store only needed data like shop, parking, … I think it is more efficient to have database architecure oriented to the need instead to have a database oriented from the data source.
2.2. Source codes¶
2.2.1. OSMDatabase class¶
The both function extractDatabaseToCSV and extractDatabaseToSQLLite works as follow:
Create database architecture (CSV or SQLite)
For each element needed (node and way)
Decode and check it based on schema
If valid store it inside database
Remove it from internal memory
import xml.etree.ElementTree as ET
import cerberus
import schema
import os,re
CONST_PROGRESS_STEP=1000
NODES_PATH = "nodes.csv"
NODE_TAGS_PATH = "nodes_tags.csv"
WAYS_PATH = "ways.csv"
WAY_NODES_PATH = "ways_nodes.csv"
WAY_TAGS_PATH = "ways_tags.csv"
SCHEMA = schema.schema
NODE_FIELDS = ['id', 'lat', 'lon', 'user', 'uid', 'version', 'changeset', 'timestamp']
NODE_TAGS_FIELDS = ['id', 'key', 'value', 'type']
WAY_FIELDS = ['id', 'user', 'uid', 'version', 'changeset', 'timestamp']
WAY_TAGS_FIELDS = ['id', 'key', 'value', 'type']
WAY_NODES_FIELDS = ['id', 'node_id', 'position']
ENDWITHDIGIT = re.compile(r'[0-9]*$')
#-------------------------------------------------------
def getInsertDictSql(dbname,key_list):
'''
Return SQLite command to insert python dict to database
'''
text=str("INSERT INTO {} ({}) VALUES ({})").format(dbname,(",").join(key_list),(',').join(['?']*len(key_list)))
return text
#-------------------------------------------------------
def toListOfTuple(list_dict):
'''
Convert list of dict data to list tupple based of dict value
'''
list_tuple=list()
for elem in list_dict:
list_tuple.append(tuple(elem.values()))
return list_tuple
#-------------------------------------------------------
class OSM_DATABASE:
'''
Class managing OSM XML file by loading and exporting it to CSV and SQLite
'''
#-------------------------------------------------------
def __init__(self,osm_file):
self.osm_file=osm_file
self.nb_elem_read=0
self.nb_elem_reject=0
#-------------------------------------------------------
def __str__(self):
return str("OSM file: {}").format(self.osm_file)
#-------------------------------------------------------
def __repr__(self):
return str(self)
#-------------------------------------------------------
def printProgress(self,force=False,step=CONST_PROGRESS_STEP):
'''
Display progress information. Print number of element loaded and rejected, and the associated ratio
'''
if force or (self.nb_elem_read+self.nb_elem_reject)%step == 0 :
print(str("number of items {:3.2f}% (read: {} | reject {})").format((self.nb_elem_read*100)/(self.nb_elem_read+self.nb_elem_reject),self.nb_elem_read,self.nb_elem_reject))
#-------------------------------------------------------
def getElement(self,tags):
'''
XML Element iterating parser function
'''
context = ET.iterparse(self.osm_file)
context= iter(context)
event, root = next(context)
for event, elem in context:
if elem.tag in tags:
yield elem
root.clear() # remove element inside memory. Allows to parse bigger XML file like SAX
#-------------------------------------------------------
def normalization(self,tag):
'''
Transform readed data
'''
# housenumber normalization: everything in uppercase
if tag["key"]== "housenumber":
tag["value"]=tag["value"].upper()
#maxspeed shall be only numerical.
#Sysntax: https://wiki.openstreetmap.org/wiki/Key:source:maxspeed
elif tag["key"]=="maxspeed" and ENDWITHDIGIT.search(tag["value"]):
tag["value"]=ENDWITHDIGIT.search(tag["value"]).group(0)
#scholl syntax adaptation
#https://wiki.openstreetmap.org/wiki/FR:Tag:amenity%3Dschool
#invert type and key
elif tag["type"].lower()=="school" and len(tag["key"])==2:
tag["key"]="school"
tag["type"]=tag["key"]
return tag
#-------------------------------------------------------
def decodeTagElement(self,element,idVal):
tag=dict()
tag["id"]=idVal
split_val=element.get("k").split(":")
tag["value"]=str(element.get("v"))
if len(split_val) > 1:
tag["key"]=str(":").join(split_val[1:])
tag["type"]=split_val[0]
else:
tag["key"]=split_val[0]
tag["type"]="regular"
return self.normalization(tag)
#-------------------------------------------------------
def decodeElement(self,element):
'''
Decode XML element ( node and way tag)
Return python dict function to the tag value: way or node
For way XML tag: dict with 'way': way_attribs, 'way_nodes': way_nodes, 'way_tags': tags
{'way': {'id': 209809850,
'user': 'chicago-buildings',
'uid': 674454,
'version': '1',
'timestamp': '2013-03-13T15:58:04Z',
'changeset': 15353317},
'way_nodes': [{'id': 209809850, 'node_id': 2199822281, 'position': 0},
{'id': 209809850, 'node_id': 2199822390, 'position': 1},
{'id': 209809850, 'node_id': 2199822392, 'position': 2},
{'id': 209809850, 'node_id': 2199822369, 'position': 3},
{'id': 209809850, 'node_id': 2199822370, 'position': 4},
{'id': 209809850, 'node_id': 2199822284, 'position': 5},
{'id': 209809850, 'node_id': 2199822281, 'position': 6}],
'way_tags': [{'id': 209809850,
'key': 'housenumber',
'type': 'addr',
'value': '1412'},
{'id': 209809850,
'key': 'building_id',
'type': 'chicago',
'value': '366409'}]
}
For node XML tag: dict with 'node': node_attribs, 'node_tags': tags
{'node': {'id': 757860928,
'user': 'uboot',
'uid': 26299,
'version': '2',
'lat': 41.9747374,
'lon': -87.6920102,
'timestamp': '2010-07-22T16:16:51Z',
'changeset': 5288876},
'node_tags': [{'id': 757860928,
'key': 'amenity',
'value': 'fast_food',
'type': 'regular'},
{'id': 757860928,
'key': 'cuisine',
'value': 'sausage',
'type': 'regular'},
{'id': 757860928,
'key': 'name',
'value': "Shelly's Tasty Freeze",
'type': 'regular'}]
}
'''
node_attribs = {}
way_attribs = {}
way_nodes = []
tags = []
if element.tag == 'node':
for att in NODE_FIELDS:
node_attribs[att]=element.get(att)
for node_tag_elem in element.findall("tag"):
tag = self.decodeTagElement(node_tag_elem,node_attribs[NODE_FIELDS[0]])
if tag : tags.append(tag)
return {'node': node_attribs, 'node_tags': tags}
elif element.tag == 'way':
for att in WAY_FIELDS:
way_attribs[att]=element.get(att)
for way_tagsubelem in element.findall("tag"):
tag = self.decodeTagElement(way_tagsubelem,way_attribs[WAY_FIELDS[0]])
if tag : tags.append(tag)
pos=0
for way_ndsubelem in element.findall("nd"):
nd=dict()
nd[WAY_NODES_FIELDS[0]]=way_attribs[WAY_FIELDS[0]]
nd[WAY_NODES_FIELDS[1]]=way_ndsubelem.get("ref")
nd[WAY_NODES_FIELDS[2]]=pos
pos+=1
way_nodes.append(nd)
return {'way': way_attribs, 'way_nodes': way_nodes, 'way_tags': tags}
#-------------------------------------------------------
def checkElement(self,element, validator, schema=SCHEMA):
'''
Check if XML element is compliant with schema
Return True if compliant if not return False and print on stdout reason
'''
if not element:
return False
if validator.validate(element, schema) is not True:
print(str("Wrong element: Element ({} ) has the following errors:{}\n").format(element,str(validator.errors)))
return False
return True
#-------------------------------------------------------
def extractDatabaseToCSV(self,folder):
'''
Extract OSM database to CSV inside specific folder
'''
import csv
nodes_file = open(os.path.join(folder,NODES_PATH),'w',newline='')
nodes_tags_file = open(os.path.join(folder,NODE_TAGS_PATH),'w',newline='')
ways_file = open(os.path.join(folder,WAYS_PATH), 'w',newline='')
way_nodes_file = open(os.path.join(folder,WAY_NODES_PATH), 'w',newline='')
way_tags_file = open(os.path.join(folder,WAY_TAGS_PATH), 'w',newline='')
nodes_writer = csv.DictWriter(f=nodes_file, fieldnames=NODE_FIELDS,delimiter=';')
node_tags_writer = csv.DictWriter(f=nodes_tags_file, fieldnames=NODE_TAGS_FIELDS,delimiter=';')
ways_writer = csv.DictWriter(f=ways_file, fieldnames=WAY_FIELDS,delimiter=';')
way_nodes_writer = csv.DictWriter(f=way_nodes_file, fieldnames=WAY_NODES_FIELDS,delimiter=';')
way_tags_writer = csv.DictWriter(f=way_tags_file, fieldnames=WAY_TAGS_FIELDS,delimiter=';')
nodes_writer.writeheader()
node_tags_writer.writeheader()
ways_writer.writeheader()
way_nodes_writer.writeheader()
way_tags_writer.writeheader()
validator = cerberus.Validator()
self.nb_elem_read=0
self.nb_elem_reject=0
for element in self.getElement(tags=('node', 'way')):
el = self.decodeElement(element)
# print(el)
if self.checkElement(el, validator):
self.nb_elem_read+=1
if element.tag == 'node':
nodes_writer.writerow(el['node'])
node_tags_writer.writerows(el['node_tags'])
elif element.tag == 'way':
ways_writer.writerow(el['way'])
way_nodes_writer.writerows(el['way_nodes'])
way_tags_writer.writerows(el['way_tags'])
else:
self.nb_elem_reject+=1
self.printProgress()
self.printProgress(force=True)
#-------------------------------------------------------
def extractDatabaseToSQLLite(self,database):
'''
Extract OSM database to SQLite
'''
import sqlite3
validator = cerberus.Validator()
if os.path.exists(database):
os.remove(database)
# create a database connection
SqlDatabase = sqlite3.connect(database)
if not SqlDatabase:
return
#Create database
DBCursor = SqlDatabase.cursor()
'''Create nodes Table
id int
lat float
lon float
user string
uid int
version int
changeset int
timestamp string
'''
DBCursor.execute('''CREATE TABLE nodes (id INTEGER PRIMARY KEY, lat REAL , lon REAL ,user TEXT, uid INTEGER, version INTEGER, changeset INTEGER, timestamp TEXT)''')
''' Create nodes_tags table
id int
key string
value string
type string
'''
DBCursor.execute('''CREATE TABLE nodes_tags (id INTEGER , key TEXT, value TEXT, type TEXT , FOREIGN KEY (id) REFERENCES nodes(id))''')
''' Create ways table
id int
user string
uid int
version int
changeset int
timestamp string
'''
DBCursor.execute('''CREATE TABLE ways (id INTEGER PRIMARY KEY, user TEXT, uid INTEGER , version INTEGER, changeset INTEGER, timestamp TEXT)''')
''' Create ways_nodes table
id int
node_id int
position int
'''
DBCursor.execute('''CREATE TABLE ways_nodes (id INTEGER, node_id INTEGER , position INTEGER, FOREIGN KEY (id) REFERENCES ways(id), FOREIGN KEY (node_id) REFERENCES nodes(id) )''')
''' Create ways_tags table
id int
key string
value string
type string
'''
DBCursor.execute('''CREATE TABLE ways_tags (id INTEGER , key TEXT, value TEXT, type TEXT , FOREIGN KEY (id) REFERENCES ways(id))''')
self.nb_elem_read=0
self.nb_elem_reject=0
for element in self.getElement(tags=('node', 'way')):
el = self.decodeElement(element)
if self.checkElement(el, validator):
self.nb_elem_read+=1
try:
if element.tag == 'node':
DBCursor.execute(getInsertDictSql("nodes",el['node'].keys()),tuple(el['node'].values()))
list_tuple=toListOfTuple(el['node_tags'])
if len(list_tuple) > 0 :
DBCursor.executemany(getInsertDictSql("nodes_tags",el['node_tags'][0].keys()),list_tuple)
elif element.tag == 'way':
DBCursor.execute(getInsertDictSql("ways",el['way'].keys()),tuple(el['way'].values()))
list_tuple=toListOfTuple(el['way_nodes'])
if len(list_tuple) > 0 :
DBCursor.executemany(getInsertDictSql("ways_nodes",el['way_nodes'][0].keys()),list_tuple)
list_tuple=toListOfTuple(el['way_tags'])
if len(list_tuple) > 0 :
DBCursor.executemany(getInsertDictSql("ways_tags",el['way_tags'][0].keys()),list_tuple)
except(e):
print(str("Exeception for elem {}:{}").format(element.tag,elem[id]))
else:
self.nb_elem_reject+=1
self.printProgress()
self.printProgress(force=True)
SqlDatabase.commit()
#-------------------------------------------------------
# Note: The schema is stored in a .py file in order to take advantage of the
# int() and float() type coercion functions. Otherwise it could easily stored as
# as JSON or another serialized format.
ANY_ASCII_STRING="[\x00-\x7FéèçàêâôÉòîö ]*" # any ascii char plus specific char
schema = {
'node': {
'type': 'dict',
'schema': {
'id': {'required': True, 'type': 'integer', 'coerce': int},
'lat': {'required': True, 'type': 'float', 'coerce': float},
'lon': {'required': True, 'type': 'float', 'coerce': float},
'user': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'uid': {'required': True, 'type': 'integer', 'coerce': int},
'version': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'changeset': {'required': True, 'type': 'integer', 'coerce': int},
'timestamp': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING}
}
},
'node_tags': {
'type': 'list',
'schema': {
'type': 'dict',
'schema': {
'id': {'required': True, 'type': 'integer', 'coerce': int},
'key': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'value': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'type': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING}
}
}
},
'way': {
'type': 'dict',
'schema': {
'id': {'required': True, 'type': 'integer', 'coerce': int},
'user': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'uid': {'required': True, 'type': 'integer', 'coerce': int},
'version': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'changeset': {'required': True, 'type': 'integer', 'coerce': int},
'timestamp': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING}
}
},
'way_nodes': {
'type': 'list',
'schema': {
'type': 'dict',
'schema': {
'id': {'required': True, 'type': 'integer', 'coerce': int},
'node_id': {'required': True, 'type': 'integer', 'coerce': int},
'position': {'required': True, 'type': 'integer', 'coerce': int}
}
}
},
'way_tags': {
'type': 'list',
'schema': {
'type': 'dict',
'schema': {
'id': {'required': True, 'type': 'integer', 'coerce': int},
'key': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'value': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING},
'type': {'required': True, 'type': 'string', "regex": ANY_ASCII_STRING}
}
}
}
}
2.2.2. OSMToCSV main program¶
The main program allows to extract data of OSM database (XML format) to CSV files by repecting the database architecture.
#!/usr/local/bin/python3
import OSMDatabase
#-------------------------------------------------------
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("osm", help="osm database path")
parser.add_argument("folder", help="extract folder path")
args = parser.parse_args()
myOsm=OSMDatabase.OSM_DATABASE(args.osm)
myOsm.extractDatabaseToCSV(args.folder)
#-------------------------------------------------------
2.2.3. OSMToSQL main program¶
The main program allows to extract data of OSM database (XML format) to SQLite database by repecting the database architecture.
#!/usr/local/bin/python3
import OSMDatabase
#-------------------------------------------------------
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("osm", help="osm database path")
parser.add_argument("sql", help="sql database path")
args = parser.parse_args()
myOsm=OSMDatabase.OSM_DATABASE(args.osm)
myOsm.extractDatabaseToSQLLite(args.sql)
#-------------------------------------------------------
2.2.4. OSMAnalysis class¶
The OSMAnalysis class manage several database request and plot. This class provide tools box for OSM data analysis.
import sqlite3 #https://docs.python.org/2/library/sqlite3.html
import pandas as pd
import matplotlib.pyplot as plt
#-------------------------------------------------------
class OSM_ANALYSIS():
'''
class allowing to analyse OSM database
'''
#-------------------------------------------------------
def __init__(self,project,database_path=None):
self.Project=project
self.Database_path=database_path
self.SQLDatabase=None
self.DatabaseCursor=None
if self.Database_path:
self.connectDatabase()
#-------------------------------------------------------
def __str__(self):
return str("Project: {} , Database_path:{} , DatabaseCursor: {}").format0(self.Project, self.Database_path,self.DatabaseCursor)
#-------------------------------------------------------
def __repr__(self):
return str(self)
#-------------------------------------------------------
def setDatabasePath(database_path):
self.Database_path=database_path
if self.DatabaseCursor:
self.closeDatabase()
#-------------------------------------------------------
def connectDatabase(self):
self.SQLDatabase = sqlite3.connect(self.Database_path)
self.DatabaseCursor = self.SQLDatabase.cursor()
#-------------------------------------------------------
def closeDatabase(self):
self.SQLDatabase.close()
self.DatabaseCursor=None
#-------------------------------------------------------
def executeQuery(self,query):
self.DatabaseCursor.execute(query)
#-------------------------------------------------------
def recordToDataFrame(self,indexCol=None):
'''
Transform answer from sqlLite to pandas dataframe. The sqlite answer is collect from DatabaseCursor
'''
cols = [column[0] for column in self.DatabaseCursor.description]
return pd.DataFrame.from_records(data = self.DatabaseCursor.fetchall(), columns = cols, index=indexCol)
#-------------------------------------------------------
def nbUniqueUsers(self):
'''
SQL lite request to get list of unique users
Return number of unique users
'''
QUERY ='''SELECT count(*) FROM (SELECT nodes.user, nodes.uid from nodes UNION SELECT ways.user, ways.uid FROM ways GROUP BY ways.uid ORDER BY ways.uid)'''
self.executeQuery(QUERY)
row = self.DatabaseCursor.fetchone()
return row[0]
#-------------------------------------------------------
def nbNodes(self):
'''
Return number of nodes
'''
QUERY ='''SELECT count(*) FROM nodes '''
self.executeQuery(QUERY)
row = self.DatabaseCursor.fetchone()
return row[0]
#-------------------------------------------------------
def nbWays(self):
'''
Return number of ways
'''
QUERY ='''SELECT count(*) FROM ways '''
self.executeQuery(QUERY)
row = self.DatabaseCursor.fetchone()
return row[0]
#-------------------------------------------------------
def uniqueUsersListSortByActivities(self):
'''
SQLLite reqest to get user list sort by activites
return Pandas data frame
'''
QUERY ='''SELECT nodes.user as user , nodes.uid as uid , count(nodes.uid) as activities from nodes UNION SELECT ways.user as user , ways.uid as uid, count(ways.uid) as activities FROM ways GROUP BY ways.uid ORDER BY activities DESC'''
self.executeQuery(QUERY)
return self.recordToDataFrame("uid")
#-------------------------------------------------------
def nodesTypeList(self):
'''
SQLLite request to get nodes unique type list with occurence (case unsensitive)
Return pandas data frame
'''
QUERY ='''SELECT nodes_tags.key as type, count(nodes_tags.key) as occurence from nodes_tags GROUP BY nodes_tags.key ORDER BY nodes_tags.key COLLATE NOCASE'''
self.executeQuery(QUERY)
return self.recordToDataFrame("type")
#-------------------------------------------------------
def nodesTypeInformation(self,type):
'''
SQLLite request to get node information of type argument ( case unsensitive)
Return pandas data frame
'''
QUERY =str('''SELECT nodes_tags.value, nodes.lat, nodes.lon, nodes.user from nodes_tags JOIN nodes ON nodes_tags.id = nodes.id WHERE nodes_tags.key = "{}" ORDER BY nodes_tags.value COLLATE NOCASE''').format(type)
self.executeQuery(QUERY)
return self.recordToDataFrame()
#-------------------------------------------------------
def nodesTypesNumber(self,types):
'''
SQLLite request to get the node types occuerence. The types argument is a python list
Return pandas data frame
'''
if not types or len(types) == 0:
QUERY =str('''SELECT nodes_tags.key as type , count(nodes_tags.key) as occurence from nodes_tags GROUP BY nodes_tags.key ORDER BY occurence DESC''')
self.executeQuery(QUERY)
return self.recordToDataFrame("type")
else:
QUERY =str('''SELECT nodes_tags.key as type , count(nodes_tags.key) as occurence from nodes_tags WHERE nodes_tags.key = "{}" ''').format(types[0])
for tp in types[1:]:
QUERY+= str('''OR nodes_tags.key = "{}" ''').format(tp)
QUERY+= '''GROUP BY nodes_tags.key ORDER BY occurence DESC'''
self.executeQuery(QUERY)
return self.recordToDataFrame("type")
#-------------------------------------------------------
def displayNodeTypeReparition(self,n_first=None,with_file=True,with_print=False):
'''
Create a plot to display the node type repartition. The requiered types is a list argument.
On option:
- print on stdout the node type repartition
- save plot to current folder
'''
title='Nodes types repartition'
nodesTypesNumber=self.nodesTypesNumber(None)
if n_first:
nodesTypesNumber=nodesTypesNumber.head(n_first)
title+= str(" ({} firsts)").format(n_first)
if with_print:
print(str("Nodes types repartition:\n{}").format(nodesTypesNumber))
fig, axs = plt.subplots(1,1)
fig.canvas.set_window_title(self.Project)
nodesTypesNumber.plot.bar(stacked=True,title=title,ax=axs)
axs.set_ylabel(nodesTypesNumber.keys()[0])
axs.set_xlabel( nodesTypesNumber.index.name)
plt.tight_layout()
if with_file:
filename=title
for ch in [" ","(",")"]:
filename=filename.replace(ch,"_")
plt.savefig(str("{}.png").format(filename))
#-------------------------------------------------------
def displayNodeTypeNumber(self,types,with_file=True,with_print=False):
'''
Create a plot to display the number of node type. The requiered types is a list argument.
On option:
- print on stdout the node type repartition
- save plot to current folder
'''
title=str('Nodes types number')
nodesTypesNumber=self.nodesTypesNumber(types)
if with_print:
print(str("Nodes types number:\n{}").format(nodesTypesNumber))
fig, axs = plt.subplots(1,1)
fig.canvas.set_window_title(self.Project)
nodesTypesNumber.plot.bar(stacked=True,title='Nodes types number',ax=axs)
axs.set_ylabel(nodesTypesNumber.keys()[0])
axs.set_xlabel( nodesTypesNumber.index.name)
plt.tight_layout()
if with_file:
filename=title
for ch in [" ","(",")"]:
filename=filename.replace(ch,"_")
plt.savefig(str("{}.png").format(filename))
#-------------------------------------------------------
def displayUsersListSortByActivities(self,n_first=None,with_file=True,with_print=False):
'''
Create a plot to display the user activities repartition.
On option:
- the number of users and the print on stdout
- save plot to current folder
'''
title='List on users sort by activities'
uniqueUsers=self.uniqueUsersListSortByActivities()
if n_first:
uniqueUsers=uniqueUsers.head(n_first)
title+= str(" ({} firsts)").format(n_first)
if with_print:
print(str("List on users sort by activities:\n{}").format(uniqueUsers))
fig, axs = plt.subplots(1,1)
fig.canvas.set_window_title(self.Project)
uniqueUsers.plot.bar(x="user", y="activities", stacked=True,title=title,ax=axs)
plt.tight_layout()
if with_file:
filename=title
for ch in [" ","(",")"]:
filename=filename.replace(ch,"_")
plt.savefig(str("{}.png").format(filename))
#-------------------------------------------------------
def showDisplay(self):
'''
show all plots
'''
plt.show()
#-------------------------------------------------------
#-------------------------------------------------------
2.2.5. Map class¶
This class implement an abstraction of folium package. The objective is to add marker to OpenStreetMap cartography.
import folium,os,sys, subprocess
from folium.plugins import MarkerCluster
#-------------------------------------------------------
ICON_INFO="info-sign"
ICON_CLOUD="cloud"
ICON_OK="ok-sign"
ICON_REMOVE="remove-sign"
#-------------------------------------------------------
class MAP: # Abstraction class alowing to display marker to OSM map.
#-------------------------------------------------------
def __init__(self,location_start,zoom_start,with_marker_cluster):
self.features=dict() # folium features dict
self.my_map = folium.Map(location=location_start,zoom_start=zoom_start, control_scale=True)
if with_marker_cluster:
self.marker_cluster = dict() # folium markers cluster dict
else:
self.marker_cluster = None
#-------------------------------------------------------
def addFeature(self,name,color):
'''
Add new feature (group) of markers cluster.
name: name of feature
color: color of the feature. Impact color name on legend
'''
if name not in self.features.keys():
self.features[name]=folium.FeatureGroup(name=str('<span style="color: {};">{}</span>').format(color,name))
if self.marker_cluster != None :
self.marker_cluster[name]=MarkerCluster()
self.features[name].add_child(self.marker_cluster[name])
#-------------------------------------------------------
def addCircleMarker(self,location,popup,tooltip,color,feature=None):
'''
Add circle marker to the feature if exist.
Circle marker properties: color, poput and tooltip
'''
if feature and feature in self.features.keys():
folium.CircleMarker(location=location,popup=popup,tooltip=tooltip,color=color).add_to(self.features[feature])
else:
folium.CircleMarker(location=location,popup=popup,tooltip=tooltip,color=color).add_to(self.my_map)
#-------------------------------------------------------
def addMarker(self,location,popup,tooltip,color,icon,feature=None):
'''Add marker to the feature/marker cluster if exist
Marker properties: color, poput and tooltip
'''
if feature and feature in self.features.keys():
if self.marker_cluster != None :
folium.Marker(location=location,popup=popup,tooltip=tooltip,icon=folium.Icon(color=color, icon=icon)).add_to(self.marker_cluster[feature])
else:
folium.Marker(location=location,popup=popup,tooltip=tooltip,icon=folium.Icon(color=color, icon=icon)).add_to(self.features[feature])
else:
folium.Marker(location=location,popup=popup,tooltip=tooltip,icon=folium.Icon(color=color, icon=icon)).add_to(self.my_map)
#-------------------------------------------------------
def save(self,path,execute=False):
'''
Generate html file to the path and execute it if requested
'''
for feat in self.features.values():
self.my_map.add_child(feat)
if len(self.features.keys()):
self.my_map.add_child(folium.map.LayerControl(collapsed=False))
self.my_map.save(path)
if execute:
self.open_file(path)
#-------------------------------------------------------
def open_file(self,filename):
'''
Execute file with default associated solfware. Compatibility to all OS (Windows, MacOS, Linux).
'''
if sys.platform == "win32":
os.startfile(filename)
else:
opener ="open" if sys.platform == "darwin" else "xdg-open"
subprocess.call([opener, filename])
#-------------------------------------------------------
2.2.6. Analysis main program¶
The Analysis main program implement and use the OSMAnalysis class.
#!/usr/local/bin/python3
import argparse
import map
import OSMAnalysis
PROJECT="OpenStreetMap Data"
CONST_COLOR_LIST=["red","green","blue","orange","purple","pink"]
CONST_SEARCH_TYPES=["parking","bus","cafes","shop","cash"]
CONST_WITH_MARKERCLUSTER=True
#-------------------------------------------------------
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("osmDatabase", help="osm sqlite database path")
parser.add_argument("--latitude", help="start latitude", default=43.3)
parser.add_argument("--longitude", help="start longitude", default=5.4)
parser.add_argument("--map_file", help="start longitude", default="my_map.html")
args = parser.parse_args()
MyOSMAnalysis=OSMAnalysis.OSM_ANALYSIS(project=PROJECT,database_path=args.osmDatabase)
nbUniqueUsers=MyOSMAnalysis.nbUniqueUsers()
print(str("Number of unique users for nodes and ways:{}\n").format(nbUniqueUsers))
NbNodes=MyOSMAnalysis.nbNodes()
print(str("Number of nodes:{}\n").format(NbNodes))
NbWays=MyOSMAnalysis.nbWays()
print(str("Number of ways:{}\n").format(NbWays))
MyOSMAnalysis.displayNodeTypeReparition(n_first=10,with_file=True,with_print=False)
MyOSMAnalysis.displayUsersListSortByActivities(n_first=10,with_file=True,with_print=False)
MyMap=map.MAP(location_start=(args.latitude,args.longitude),zoom_start=13,with_marker_cluster=CONST_WITH_MARKERCLUSTER)
index_color=0
for stype in CONST_SEARCH_TYPES:
nodesTypeInfo=MyOSMAnalysis.nodesTypeInformation(stype)
MyMap.addFeature(stype,CONST_COLOR_LIST[index_color])
for index, row in nodesTypeInfo.iterrows():
popup=str("{}:{}").format(stype,row["value"])
MyMap.addMarker(location=(row["lat"], row["lon"]),popup=popup,tooltip=stype,color=CONST_COLOR_LIST[index_color],icon=map.ICON_INFO,feature=stype)
index_color+=1
if index_color >= len(CONST_COLOR_LIST):
index_color=0
MyMap.save(args.map_file,execute=True)
MyOSMAnalysis.showDisplay()
MyOSMAnalysis.closeDatabase()
#-------------------------------------------------------