2. Database exploration¶
2.1. Statistics¶
First step, I explore the database by loading it. Then, I realize some basic statistics. TO do that , I transform python dict to pandas dataframe.
### features_list is a list of strings, each of which is a feature name.
### The first feature must be "poi".
features_list = [myTools.CONST_POI_LABEL,myTools.CONST_SALARY_LABEL,myTools.CONST_BONUS_LABEL,myTools.CONST_TOTAL_PAYMENTS_LABEL,\
myTools.CONST_TOTAL_STOCK_VALUE_LABEL,myTools.CONST_EXERCISED_STOCK_OPTIONS_LABEL,myTools.CONST_RESTRICTED_STOCK_LABEL]
### Load the dictionary containing the dataset
with open("final_project_dataset.pkl", "rb") as data_file:
data_dict = pickle.load(data_file)
#------------------------------------------------------------------
# DATA EXPLORATION
#------------------------------------------------------------------
EnronDataFrame = pd.DataFrame.from_dict(data_dict, orient='index')
# export ENRON database for documentation
EnronDataFrame.to_csv("ENRON_DATABASE.csv",sep=";")
EnronDataFrame.head(10).to_csv("ENRON_DATABASE_REDUCED.csv",sep=";")
print("Enron database statistic:")
print(EnronDataFrame.describe().transpose())
print(str("Number of data points: {}").format(EnronDataFrame[myTools.CONST_POI_LABEL].size))
print(str("Number of person of interest: {}").format(EnronDataFrame[myTools.CONST_POI_LABEL].sum()))
print(str("Number of non person of interest: {}").format(EnronDataFrame[myTools.CONST_POI_LABEL].size-EnronDataFrame[myTools.CONST_POI_LABEL].sum()))
print(str("number of features used: {}. details:({})").format(len(features_list),features_list))
FeatureNaNNumber=dict()
for feature in myTools.CONST_ALL_FEATURES:
FeatureNaNNumber[feature]=(EnronDataFrame[feature]=="NaN").sum()
FeatureNaNNumberDataFrame = pd.DataFrame.from_dict(FeatureNaNNumber, orient='index',columns=['NaN number'])
print("Number of NaN by feature:",FeatureNaNNumberDataFrame.sort_values(by='NaN number',ascending=False))
salary |
to_messages |
deferral_payments |
total_payments |
loan_advances |
bonus |
email_address |
restricted_stock_deferred |
deferred_income |
total_stock_value |
expenses |
from_poi_to_this_person |
exercised_stock_options |
from_messages |
other |
from_this_person_to_poi |
poi |
long_term_incentive |
shared_receipt_with_poi |
restricted_stock |
director_fees |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ALLEN PHILLIP K |
201955 |
2902 |
2869717 |
4484442 |
NaN |
4175000 |
-126027 |
-3081055 |
1729541 |
13868 |
47 |
1729541 |
2195 |
152 |
65 |
False |
304805 |
1407 |
126027 |
NaN |
|
BADUM JAMES P |
NaN |
NaN |
178980 |
182466 |
NaN |
NaN |
NaN |
NaN |
NaN |
257817 |
3486 |
NaN |
257817 |
NaN |
NaN |
NaN |
False |
NaN |
NaN |
NaN |
NaN |
BANNANTINE JAMES M |
477 |
566 |
NaN |
916197 |
NaN |
NaN |
-560222 |
-5104 |
5243487 |
56301 |
39 |
4046157 |
29 |
864523 |
0 |
False |
NaN |
465 |
1757552 |
NaN |
|
BAXTER JOHN C |
267102 |
NaN |
1295738 |
5634343 |
NaN |
1200000 |
NaN |
NaN |
-1386055 |
10623258 |
11200 |
NaN |
6680544 |
NaN |
2660303 |
NaN |
False |
1586055 |
NaN |
3942714 |
NaN |
BAY FRANKLIN R |
239671 |
NaN |
260455 |
827696 |
NaN |
400000 |
-82782 |
-201641 |
63014 |
129142 |
NaN |
NaN |
NaN |
69 |
NaN |
False |
NaN |
NaN |
145796 |
NaN |
|
BAZELIDES PHILIP J |
80818 |
NaN |
684694 |
860136 |
NaN |
NaN |
NaN |
NaN |
NaN |
1599641 |
NaN |
NaN |
1599641 |
NaN |
874 |
NaN |
False |
93750 |
NaN |
NaN |
NaN |
BECK SALLY W |
231330 |
7315 |
NaN |
969068 |
NaN |
700000 |
NaN |
NaN |
126027 |
37172 |
144 |
NaN |
4343 |
566 |
386 |
False |
NaN |
2639 |
126027 |
NaN |
|
BELDEN TIMOTHY N |
213999 |
7991 |
2144013 |
5501630 |
NaN |
5249999 |
NaN |
-2334434 |
1110705 |
17355 |
228 |
953136 |
484 |
210698 |
108 |
True |
NaN |
5521 |
157569 |
NaN |
|
BELFER ROBERT |
NaN |
NaN |
-102500 |
102500 |
NaN |
NaN |
NaN |
44093 |
NaN |
-44093 |
NaN |
NaN |
3285 |
NaN |
NaN |
NaN |
False |
NaN |
NaN |
NaN |
3285 |
BERBERIAN DAVID |
216582 |
NaN |
NaN |
228474 |
NaN |
NaN |
NaN |
NaN |
2493616 |
11892 |
NaN |
1624396 |
NaN |
NaN |
NaN |
False |
NaN |
NaN |
869220 |
NaN |
Number of data points: 146
Number of person of interest: 18
Number of non person of interest: 128
number of features used: 6. details:([‘poi’, ‘salary’, ‘bonus’, ‘total_payments’, ‘total_stock_value’, ‘exercised_stock_options’,’restricted_stock’])
Missing value repartition
features |
NaN number |
|---|---|
loan_advances |
142 |
director_fees |
129 |
restricted_stock_deferred |
128 |
deferral_payments |
107 |
deferred_income |
97 |
long_term_incentive |
80 |
bonus |
64 |
shared_receipt_with_poi |
60 |
from_this_person_to_poi |
60 |
from_messages |
60 |
from_poi_to_this_person |
60 |
to_messages |
60 |
other |
53 |
salary |
51 |
expenses |
51 |
exercised_stock_options |
44 |
restricted_stock |
36 |
email_address |
35 |
total_payments |
21 |
total_stock_value |
20 |
poi |
0 |
Conclusion, it will be better to select features with low NaN rate (eg total_payments). The selected features are confirm:
salary
bonus
total_payments
total_stock_value
exercised_stock_options
restricted_stock
2.2. Outliers¶
In this step, I want to detect outliers and think about the associated added value.
#------------------------------------------------------------------
# OUTLIER INVERTIGATION
#------------------------------------------------------------------
# Convert all string type of selected feature to numeric. In case of error, the value is set to NaN
EnronDataFrame=EnronDataFrame[features_list]
for feature in features_list:
if myTools.isNumeric(feature):
EnronDataFrame[feature]=EnronDataFrame[feature].apply(pd.to_numeric,errors='coerce')
# Raplace NaN value to 0.0 on all data frame not only on selected features
EnronDataFrame=EnronDataFrame.fillna(0.0)
myTools.pyplot_scatter(data=EnronDataFrame,label_x=myTools.CONST_SALARY_LABEL,label_y=myTools.CONST_BONUS_LABEL,fileName="withOutlier.png",show=True,title="ORIGINAL DATA REPARTITION")
# Display 5 first employe for each feature. Objective: identify name of plotted data
print("Outlier:")
for feature in features_list:
print(str("Sorted by {}:{}").format(feature,EnronDataFrame.sort_values(by=feature,ascending=False).head(5)))
print()
# remove OUTLIER TOTAL from data frame
EnronDataFrame=EnronDataFrame.drop(["TOTAL"])
myTools.pyplot_scatter(data=EnronDataFrame,label_x=myTools.CONST_SALARY_LABEL,label_y=myTools.CONST_BONUS_LABEL,fileName="withoutOutlier.png",show=True,title="DATA REPARTITION WITHOUT OUTLIER")

I clearly identify inside this picture an outlier. To identify it, I sort database by all feature:
Database sorted by salary
name |
poi |
salary |
bonus |
total_payments |
total_stock_value |
exercised_stock_options |
|---|---|---|---|---|---|---|
TOTAL |
False |
26704229.0 |
97343619.0 |
309886585.0 |
434509511.0 |
311764000.0 |
SKILLING JEFFREY K |
True |
1111258.0 |
5600000.0 |
8682716.0 |
26093672.0 |
19250000.0 |
LAY KENNETH L |
True |
1072321.0 |
7000000.0 |
103559793.0 |
49110078.0 |
34348384.0 |
FREVERT MARK A |
False |
1060932.0 |
2000000.0 |
17252530.0 |
14622185.0 |
10433518.0 |
PICKERING MARK R |
False |
655037.0 |
300000.0 |
1386690.0 |
28798.0 |
28798.0 |
Database sorted by bonus
name: |
poi |
salary |
bonus |
total_payments |
total_stock_value |
exercised_stock_options |
|---|---|---|---|---|---|---|
TOTAL |
False |
26704229.0 |
97343619.0 |
309886585.0 |
434509511.0 |
311764000.0 |
LAVORATO JOHN J |
False |
339288.0 |
8000000.0 |
10425757.0 |
5167144.0 |
4158995.0 |
LAY KENNETH L |
True |
1072321.0 |
7000000.0 |
103559793.0 |
49110078.0 |
34348384.0 |
SKILLING JEFFREY K |
True |
1111258.0 |
5600000.0 |
8682716.0 |
26093672.0 |
19250000.0 |
BELDEN TIMOTHY N |
True |
213999.0 |
5249999.0 |
5501630.0 |
1110705.0 |
953136.0 |
The TOTAL field is an error of loaded database. It doesn’t represent an Enron employe. Wed can remove it.
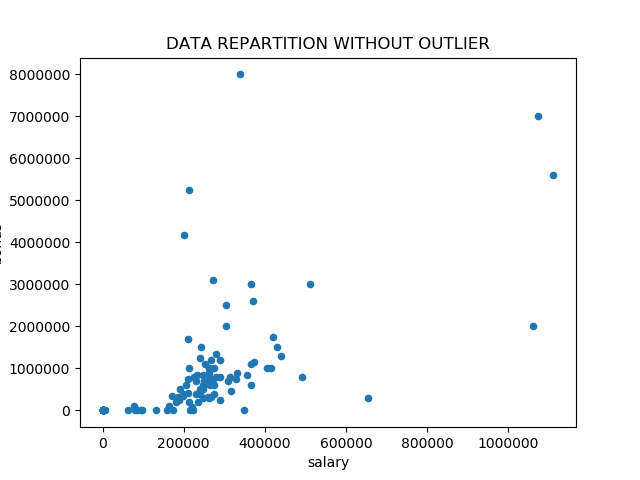
Based on this graph, we can consider two other outliers :
FREVERT MARK A: with high salary but low bonus
LAVORATO JOHN J : with high bonus and low salary
Neverthelless, this data correspond to real persons. This incoherence raise probably an indicator for POI. I keep this data.
Warning
I have two possibility for person with NaN value on features. Drop it or replace NaN to 0.0. If i drop it, the number of available data for algorithm is reduced and so the score is not suffisant. I choose to replace NaN value to 0.0 even if it is not the same information.